Clickable World: Robot Assisted Augmented Reality





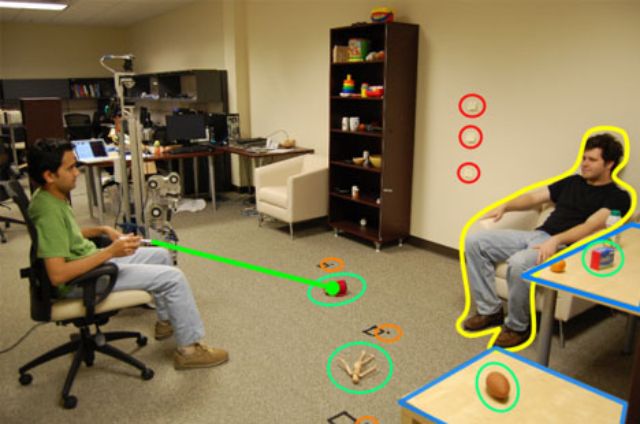
Virtual reality, augmented reality and everyday reality (and robots!) combine in this ingenious technology that transforms an ordinary room into something more than the sum of its architecture, living occupants or interior objects – a real-life work, play and/or living space you control with clicks and commands just like you do the desktop of your personal computer.
The possibilities for the disabled (or extremely lazy) of this so-called Clickable World Interface are essentially endless: point, click and identify a target to be acted on by a nearby robot. This idea is also ingeniously low-tech, requiring only an ordinary off-the-shelf laser pointer that turns into a powerful highlighter in its new application.
What what of the targets identified? The interactive potential is likewise limitless: it could be a person to whom you wish to deliver a message, and object you would like retrieved or delivered (which the robot will find, lift and hold until further instructed) or even a real-life ‘button’ with a preselected function unrelated to its physical location or other intrinsic properties.

“We present a new behavior selection system for human-robot interaction that maps virtual buttons overlaid on the physical environment to the robot’s behaviors, thereby creating a clickable world. The user clicks on a virtual button and activates the associated behavior by briefly illuminating a corresponding 3D location with an off-the-shelf green laser pointer. As we have described in previous work, the robot can detect this click and estimate its 3D location using an omnidirectional camera and a pan/tilt stereo camera. In this paper, we show that the robot can select the appropriate behavior to execute using the 3D location of the click, the context around this 3D location, and its own state.”

“For this work, the robot performs this selection process using a cascade of classifiers. We demonstrate the efficacy of this approach with an assistive object-fetching application. Through empirical evaluation, we show that the 3D location of the click, the state of the robot, and the surrounding context is sufficient for the robot to choose the correct behavior from a set of behaviors and perform the following tasks: pick-up a designated object from a floor or table, deliver an object to a designated person, place an object on a designated table, go to a designated location, and touch a designated location with its end effector.”